



The 132nd episode of Datacast is my conversation with Suresh Srinivas, who is leading the OpenMetadata Project to build Metadata APIs & specifications and a single place to discover, collaborate, and get your data right.
Our wide-ranging conversation touches on his early career working at Sylantro Systems, his contribution to Apache Hadoop at Yahoo, his journey co-founding Hortonworks and bringing Hadoop to enterprise customers, his experience at Uber scaling its data platform, the founding story of the OpenMetadata project, design principles for modern metadata platform, lessons learned from hiring & fundraising, and much more.
Please enjoy my conversation with Suresh!
Show Notes
(01:53) Suresh went over his college experience studying Electronics Engineering from the National Institute of Technology Karnataka.
(04:35) Suresh recalled his 9-year engineering career at Sylantro Systems.
(08:47) Suresh talked about the origin of Apache Hadoop at Yahoo.
(11:05) Suresh dissected the high-level design architecture of the Hadoop Distributed File System (HDFS).
(15:36) Suresh reflected on his decision to become the co-founder of Hortonworks - which focused on bringing Hadoop training and support to enterprise customers.
(17:36) Suresh unpacked the evolution of the Hortonworks Data Platform - which includes Hadoop technology such as HDFS, MapReduce, Pig, Hive, HBase, ZooKeeper, and additional components.
(20:30) Suresh shared his lessons from developing and supporting open-source software designed to manage big data processing.
(23:43) Suresh walked through the evolution of Uber’s Data Platform.
(28:03) Suresh described Uber's journey toward better data culture from first principles.
(34:00) Suresh explained his motivation to start the OpenMetadata Project.
(37:21) Suresh elaborated on the 5 design principles of OpenMetadata: schema-first, extensibility, API-centric, vendor-neural, and open-source.
(40:17) Suresh highlighted OpenMetadata's built-in features to power multiple applications, such as data collaboration, metadata versioning, and data lineage.
(44:38) Suresh emphasized his priority for the open-source roadmap to adapt to the community's needs.
(47:05) Suresh explained the architecture of OpenMetadata - which goes deep into the push-based and pull-based characteristics of metadata ingestion and consumption.
(51:47) Suresh shared the long-term vision of his new company Collate, which powers the OpenMetadata initiative.
(53:36) Suresh shared valuable hiring lessons as a startup founder.
(56:30) Suresh shared fundraising advice to founders who want to seek the right investors for their startups.
(57:50) Closing segment.
Suresh's Contact Info
OpenMetadata's Resources
Mentioned Content
People
Book
The Innovator's Dilemma (by Clayton Christensen)
About the show
Datacast features long-form, in-depth conversations with practitioners and researchers in the data community to walk through their professional journeys and unpack the lessons learned along the way. I invite guests coming from a wide range of career paths — from scientists and analysts to founders and investors — to analyze the case for using data in the real world and extract their mental models (“the WHY and the HOW”) behind their pursuits. Hopefully, these conversations can serve as valuable tools for early-stage data professionals as they navigate their own careers in the exciting data universe.
Datacast is produced and edited by James Le. For inquiries about sponsoring the podcast, email khanhle.1013@gmail.com.
Subscribe by searching for Datacast wherever you get podcasts, or click one of the links below:
If you’re new, see the podcast homepage for the most recent episodes to listen to, or browse the full guest list.
Key Takeaways
Here are the highlights from my conversation with Suresh:
On His Education
Here's a quick background on the National Institute of Technology:
Located in India, it is a reasonably unique institution. The college I attended is one of the top 10 colleges in India. What sets the National Institute of Technology (NITK) apart is its philosophy of providing representation to all the different states in India.
India is known for its diversity, with each state having its own language, culture, and cuisine. Studying at NITK allowed me to interact with students from all over India, which allowed me to experience different cultures and make lifelong friends.
Another unique aspect of the college is that it is centrally funded by the government. This makes education more affordable and provides access to world-class facilities and excellent faculty. Learning at NITK was indeed an amazing experience.
The college also had its own beach, right next to the Arabian Sea. The campus itself was equipped with fantastic facilities. Living away from home for the first time and being independent was truly the best time of my life. NITK is definitely one of the best colleges to attend in India.
During that time, electronics and computer science were the top two engineering branches. Although I had been programming from a young age, I wanted to better understand how things work. That's why I chose to study electronics and communication. As part of this program, I also had the opportunity to learn programming and delve into computer science.
My decision to start with hardware was driven by my desire to establish a strong foundation in the field.
On His Early Engineering Career at Sylantro Systems

Sylantro Systems is where I learned most of what I know today. To give you a quick background, Sylantro Systems was involved in the telecommunications industry in 1996 when a telecom act was passed in the US. This act aimed to promote competition and innovation in the market by allowing companies other than the incumbent local exchange carriers (ILECs) to offer telecommunication services.
During this time, IP telephony (ISO IP) was a popular technology, and Sylantro Systems played a significant role in developing telecommunication services for providers in this field. I had the privilege of joining this startup early on and working with talented colleagues, including senior engineers. We utilized cutting-edge technologies such as C++, early Java, in-memory databases, and real-time RPC mechanisms to build a complex distributed system that needed to be highly available.
Over nine years, I gained valuable experience and learned a great deal. However, towards the end, the company faced challenges. In 1999, the stock market crashed, making it difficult for smaller companies to compete with larger ones in providing telecommunication services. Additionally, the rise of mobile communication overshadowed business communication and landline services, shifting the focus to mobile phones.
As a small company, selling to large telecom carriers like AT&T and Verizon required significant resources and a long sales cycle. Startups often lack the financial stability and staying power needed for such endeavors. Eventually, due to changing market dynamics and a shift in our target customer segment, the startup ended sooner than expected.
On Building Apache Hadoop at Yahoo

First, I am very fortunate to have had the opportunity to work at Yahoo on Hadoop. Before that, I had experience working on distributed systems in the telecommunications industry. I was strongly interested in web-scale technologies, and Hadoop was one of them. I was lucky enough to be able to work with this technology.
To provide some background on how Hadoop came about, Yahoo, a search company, needed to build a web map for search indexing purposes. At that time, the internet was growing at an incredible pace, and the initial technology we had for collecting and storing the web map was not scaling properly. We faced limitations in scalability, with a limit of a thousand nodes, and operational challenges in adding new nodes and handling node failures.
All of these issues were quite difficult with the previous technology we had. Around that time, Google published two papers on Google File System and MapReduce. We decided to take inspiration from these papers and develop a technology similar to MapReduce called Hadoop.
Initially, we considered building this technology within Yahoo. However, we discovered that there was already a project called Hadoop, which was in its early stages. We thought it would be interesting to take the great technologies that Google had as their secret sauce and make them available to everyone.
So, we decided to develop Hadoop as an open-source project and started contributing to it. Within a year, we had a 500-node cluster up and running. We continued to scale and found that the decision to contribute to open source and make this technology available worked out really well. Eventually, Hadoop was adopted by other tech giants like Facebook, Twitter, and LinkedIn for large-scale data processing.
On Architecting HDFS
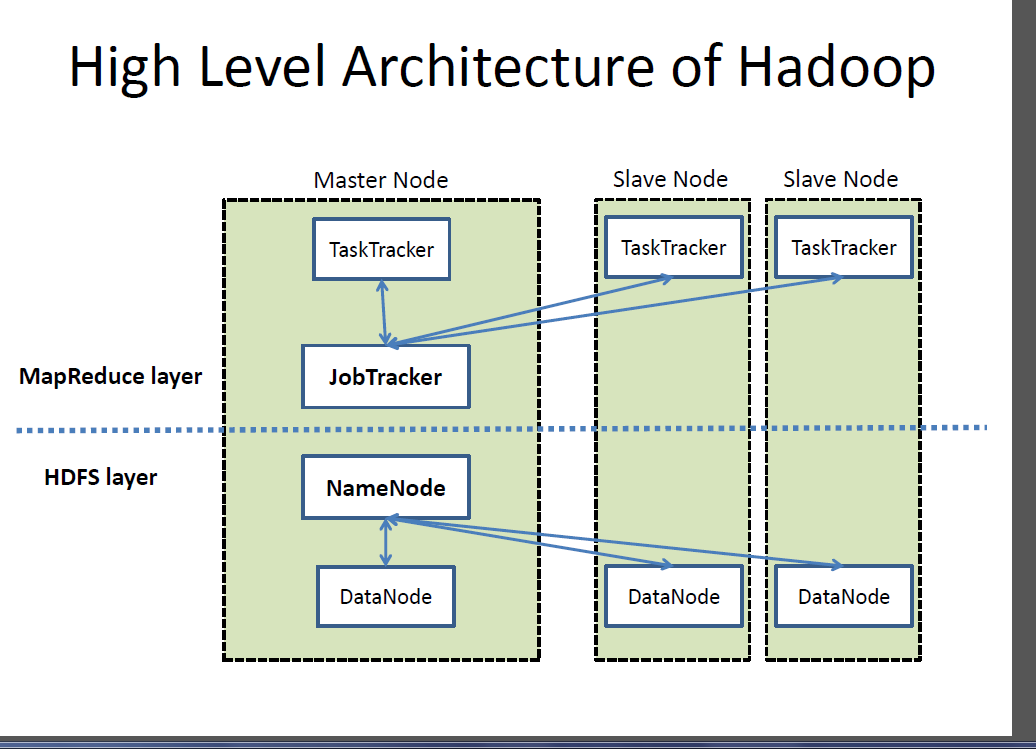
When Hadoop started, it consisted of two projects: the Hadoop Distributed File System (HDFS) and the MapReduce system. I primarily focused on the HDFS.
Before Hadoop, scalable storage required the purchase of NFS servers or similar solutions. The limitation of accessing data at a large scale was the bandwidth of the NFS system, which restricted the amount of data that could be consumed. Hadoop introduced a few fundamental changes to big data processing. Firstly, it allowed for the use of commodity nodes, eliminating the need for specialized hardware. Additionally, Hadoop enabled horizontal scaling by adding more nodes to increase storage and compute power.
Another significant change was the shift from traditional methods of bringing data to where it needs to be processed. Instead, Hadoop introduced the concept of sending the computation job to where the data is located. This approach revolutionized large-scale data processing by leveraging huge bandwidth capabilities.

Let's focus on the Hadoop Distributed File System (HDFS). It consists of a set of commodity nodes that store the file system namespace, including file names and directory structure. The namespace is stored in the name node, a journaling file system. The name node frequently checkpoints and stores the entire namespace in memory. Multiple name nodes can be used for high availability.
Regarding data storage, Hadoop is designed for handling large file sizes, such as terabytes or hundreds of megabytes. Each large file is divided into blocks, which are stored on multiple nodes. For example, a file with three blocks may have its first block stored in nodes one, two, and three, while the second block is stored in nodes six, eight, and eleven. The replication factor determines the number of copies of each block, ensuring availability in case of block loss.
With data distributed across nodes, MapReduce allows computation jobs to be scheduled close to the blocks they require. This approach optimizes workload distribution based on data location. The simplicity of this architecture, with a single name node containing the namespace and data distributed across nodes, contributed to its operational efficiency within a year. Over time, Hadoop scaled to 5,000 nodes, storing hundreds of petabytes within Yahoo. Other web companies like Facebook, Twitter, and LinkedIn also adopted this architecture.
On Co-Founding Hortonworks
I enjoy working in startups because I am naturally inclined to build things, and startups provide excellent opportunities for that. Therefore, I always looked for a chance to return to a startup environment. Fortunately, a great opportunity arose when Hadoop started gaining traction beyond web companies, and enterprises were eager to adopt it due to the ongoing digital transformation and the resulting surge in data volumes.
Thanks to its reliance on commodity hardware, Hadoop offered the most cost-effective solution for processing large amounts of data at scale. This generated significant interest from the venture capital community in starting a company outside of Yahoo as Hadoop's reach expanded beyond web companies.
We had a product that met market demand, along with the backing of exceptional venture capitalists. Despite the time it took to secure support from Yahoo, we eventually obtained it. This made the decision to go ahead with the startup a no-brainer.
In fact, compared to other startups I have worked in, this one was safe. We had funding, a market, and the necessary technology. We already had a product built and available in the open-source community. It was an obvious choice.
On the Hortonworks Data Platform

When we started Hortonworks, our initial assumption was that we already had a product to sell in a highly demanded-market. However, the reality turned out to be quite different. We had developed technology at Yahoo that worked well within their engineering-heavy environment, where they could handle tasks like operationalizing, installing, and managing the software.
But when we launched Hortonworks, we quickly realized that in order to sell our product, we needed to provide installation, upgrading, and management capabilities. This required creating a ticketing system and packaging the software to support various Linux distributions. These were all tasks we initially did not have in place, so it took us nearly a year to build everything.
As part of this process, we developed a new project called Ambari to handle installation, upgrading, and management.
Additionally, within Yahoo's Hadoop ecosystem, we primarily used Pig for data processing. However, the market had a strong demand for an SQL-based approach. So, we had to adopt Hive and invest heavily in integrating it into our stack.
HBase was another technology we had not been using extensively at Yahoo, but we decided to support it due to its popularity.
We also added Apache Kafka to our stack because it was in high demand.
At the same time, we recognized the need for streaming capabilities, so we incorporated Apache Storm.
To make our product usable and manageable, we had to build various missing pieces, such as ingestion mechanisms. This required a significant amount of time and effort. We even added support for Windows because Microsoft wanted Windows compatibility for Hadoop.
Ultimately, we ended up with a large technology stack that supported multiple projects and worked on both Linux and Windows platforms. Building this extensive and comprehensive stack was a significant undertaking.
On Lessons Building Open-Source Software

Here are a few lessons we learned:
First, when we started our company after working as engineers at Yahoo, we continued to treat Yahoo as our customer instead of understanding our actual customers, which were enterprise customers. This led us to focus on scaling and efficiency of the platform and computation rather than on efficiency and ease of use for our actual customers.
Second, we should have prioritized making our product easy to use and improving people's efficiency and developer productivity. Other technologies emerged and, in some cases, surpassed Hadoop due to their ease of use and operational efficiency. Developer productivity became increasingly important.
Third, we should have been more selective and said no to certain things. By focusing short-term on customer needs, we built many things that were not core to our technology. It's important to play the long game and resist the temptation of prioritizing today's revenue over building for the future of our company.
Lastly, it is crucial to get our first product right before expanding into a multi-product company. We need to maintain a strong focus on our customers and their personas and prioritize ease of use and productivity.
On The Evolution of Uber’s Data Platform
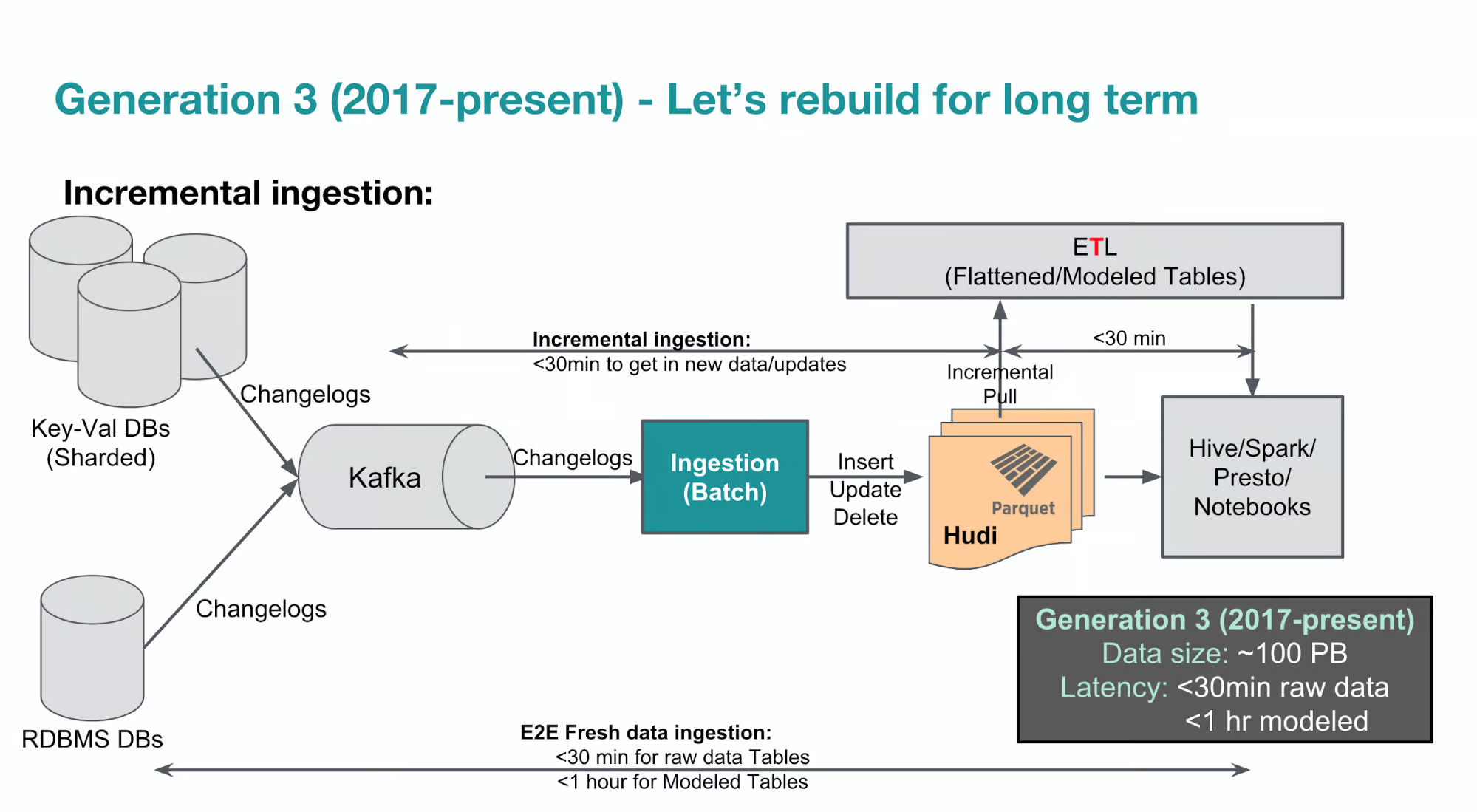
Uber is a data-driven company that relies on real-time streaming data. Due to this, Uber has made significant investments in technology platforms, data teams, and personnel. However, there have been challenges related to using data at Uber, including difficulties in utilizing the data effectively and reliability issues.
Uber initially attempted to address these challenges by hiring more data scientists. However, it became apparent that a more fundamental approach was necessary to tackle the root causes of these problems rather than treating the symptoms.
The first issue examined was the difficulty in using Uber's data. Uber had adopted a microservices architecture, with thousands of microservices and their own APIs and schemas. This resulted in inconsistent definitions, even for core types like location. For example, some microservices referred to location as a point, while others referred to it as a location. Additionally, the number of fields and their structure varied across different microservices.
Uber developed 90 standard types for core concepts such as location, address, and exchange rate to address this. These standardized types were gradually adopted across all microservices, ensuring consistent vocabulary and structure for online data.
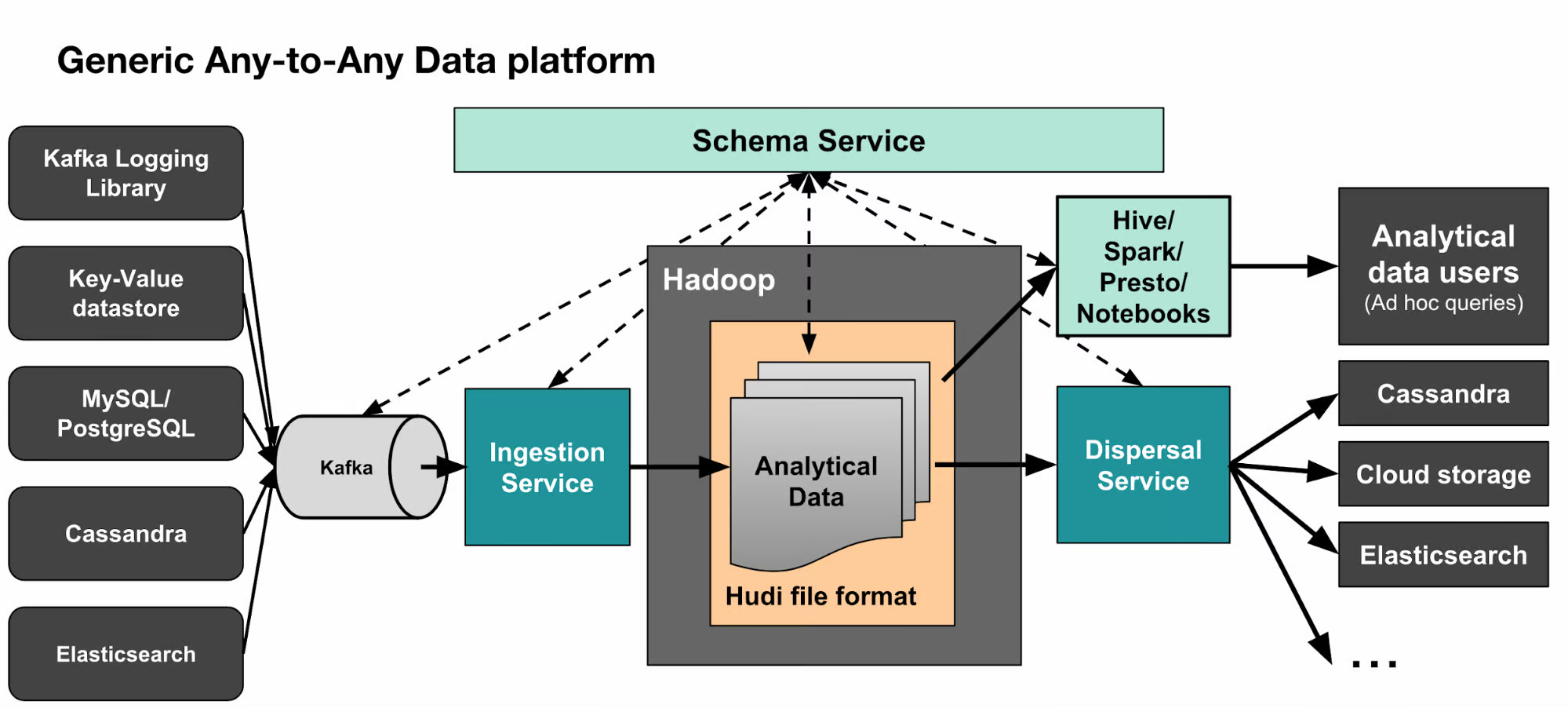
Another challenge was the flow of data from online to offline systems, where it underwent transformations for various use cases such as dashboards, metrics, and machine learning models. With hundreds of thousands of tables and queries, simply addressing data quality at the end was ineffective. Instead, Uber took an end-to-end approach and focused on ensuring schema compliance throughout the data flow process. This involved code reviews and establishing a central data engineering team to improve data practices.
By adopting these first principles and implementing an end-to-end approach, Uber aimed to make its data more reliable and better suited for various purposes.
On Uber's journey toward better data culture from first principles
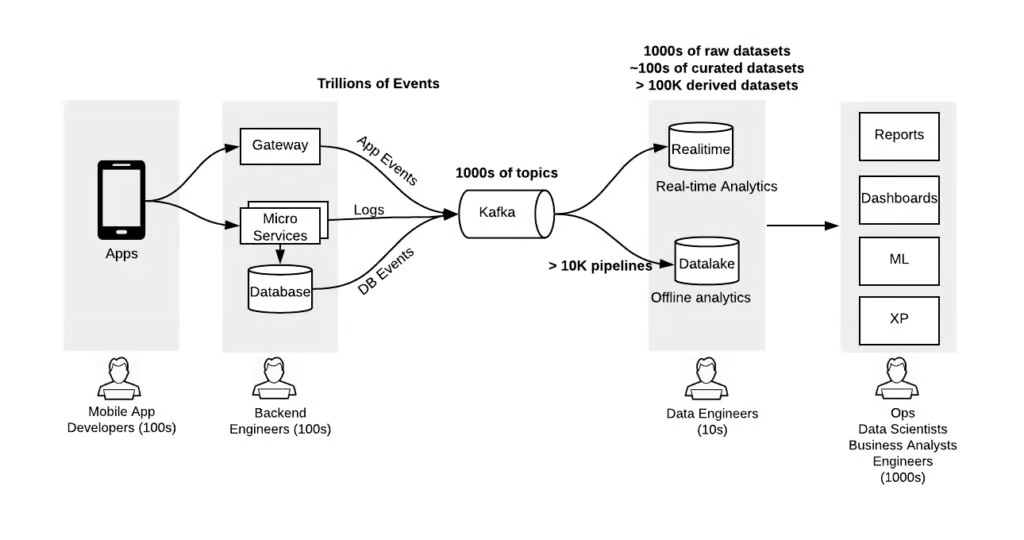
If we look at what has happened in the last 10 years, there has been a data explosion and the availability of platforms that provide high scalability for storage and compute. However, despite all of this, people are still practicing data in an ad hoc manner. There is no process or thinking behind it. Instead, people simply react to the explosion of data and availability of platforms without considering how they are handling data.
We must ask ourselves how to improve our data practices instead of taking a band-aid approach. At Uber, we stepped back and approached the problem from first principles. The first thing we realized was that data was being changed randomly without any understanding of the impact on downstream data sets. There was no awareness of how others were using the data. This led to schema incompatibility and broke downstream code dependent on compatible schemas.
To address this, we treated data changes like code changes. We introduced tests for backward incompatibility and ensured that any new events were clearly understood and published. We also implemented code reviews and schema reviews to reduce the occurrence of bad data at its source.
Another issue we tackled was the proliferation of data sets. People would create their own copies of data without proper ownership or guarantees. We implemented data ownership, where important data was owned by a team instead of an individual. This made data quality more reliable and accountable.
Furthermore, we recognized the importance of data quality. Even though applications may work well initially, data problems such as missing or incorrect data can cause reliability issues. It is crucial to know the quality of the data and address any issues promptly to ensure accurate reporting and decision-making.
We also focused on improving productivity and user experience by consolidating tools and building features tailored for data consumers. This reduced manual work and enhanced overall efficiency.
Lastly, we emphasized the organization and prioritization of data. We implemented the principle of domain ownership, where a domain is responsible for both online and offline data. This facilitated better communication and coordination between teams working on different aspects of data processing.

In summary, we need to approach data with more structure and discipline to improve our data practices. We can build trust in our data and achieve reliable outcomes by implementing testing, ownership, data quality monitoring, tool consolidation, and domain ownership.
On Leading the OpenMetadata Project
When it comes to transforming Uber's data culture, the key lesson we learned is that understanding your data is crucial. Proper understanding can help you achieve a lot. You can utilize the data, address issues, and transform the culture. From this perspective, metadata plays a critical role.
Data is often referred to as an asset, and we believe that metadata is the key to unlocking its value. However, information and knowledge about data are currently not well-tracked or stored in a shareable and centralized manner. By addressing the metadata problem, which is currently mainly used for discovery purposes, we can also solve other issues, such as data quality, reliability, and the lack of collaboration among people.
Collaboration is a significant missing piece in the world of data today, as data moves from person to person. Metadata provides the answer to this problem and can solve most of the issues that plague the world of data. Many companies are already building their own metadata systems, including myself having built two in the past. This is my third iteration. We recognized the importance of a centralized and shareable metadata system for ensuring data accuracy. However, the existing open-source metadata systems may not suit everyone's needs as they are tailored to specific companies. That's why Uber's metadata project was not open-sourced. Instead, we built it from scratch, focusing on the right architectural principles and technology choices that can be applicable across organizations.
Open Metadata is an attempt to build a metadata project using metadata standards and APIs to solve the metadata problem once and for all. This approach allows us to concentrate on innovating around metadata, unleashing its full potential.
On OpenMetadata's Design Principles
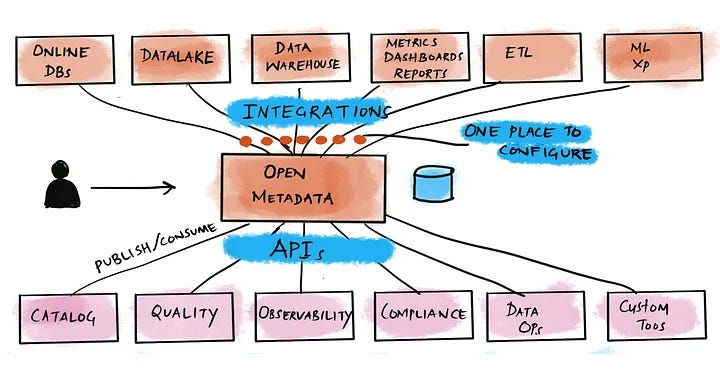
Let's explore the different metadata systems available today. Most of these systems are not even built by data practitioners.
Data practitioners understand the importance of a schema to consume data effectively. A good schema can make data easy to consume, while a bad schema can make it difficult and lead to mistakes. Surprisingly, many data practitioners build metadata systems without considering the schema for metadata as an important factor.
As a result, they end up creating implementations with simple key-value pairs, lacking strong typing. This is how most metadata systems are built: glorified key-value pairs without robust typing. At Uber, we realized that the lack of a core vocabulary made data hard to use. We wanted to apply the same principle of data standardization to metadata. This means having strongly typed schemas for entities, which are built using reusable strongly typed types. These schemas serve as building blocks and provide a vocabulary for metadata.
Standardizing metadata is crucial if you want to share your metadata stored in the metadata system with others. Currently, metadata is not easily shareable across systems. Each system, such as data quality or observability systems, only has partial metadata about tables and databases.
This is because systems cannot share what is already stored elsewhere due to vendor-specific formats and missing APIs. We aim to change this by adopting a schema-first approach. This approach ensures that metadata is consumable and allows for connecting all data and data systems in a central metadata repository. This repository can then be accessed through APIs, enabling any tool to reuse existing metadata.
The approach must be vendor-neutral, community-driven, and operate in an open and standardized space to achieve this. This is why we initiated this project as an open-source endeavor.
On OpenMetadata's Built-In Features
Start with our hypothesis that many applications can benefit if you have centralized, shared, consistent metadata.
Metadata is typically used for discovery, right? You refer to it as data catalogs. It helps people find existing data for governance, right? It allows for tagging and other functionalities. Many possibilities can be explored. However, collaboration is currently a missing piece that remains unsolved by anyone.
Everyone talks about supporting collaboration, but what we mean by collaboration is the interaction between data producers and data consumers. Data scientists, for example, should be able to have conversations around the data itself. If some description is missing, there should be no need to create a Jira ticket just for that purpose, as it often goes unnoticed.
No one has addressed this issue. Jira and descriptions rarely get updated, right? What we have developed is an activity feed. It lets you stay informed about all the changes to your data. It notifies you when someone tags Personally Identifiable Information (PII) when new data is published or when schema changes, failures, or backfilling processes exist.
All these events are presented as activity feeds. You can filter them and understand what is happening with the data you are interested in. You can also start conversations, ask questions, and request descriptions directly in the activity feed. These requests become tasks assigned to the data owners. This is the kind of collaboration we are working on.

Additionally, data lineage is a form of metadata. It is part of the metadata versioning process, which tracks how data has changed over time. We are currently working on something similar to what we did at Uber. We built a data quality system, a data observability system, a data compliance system, and a data management system. These were all standalone systems with their own databases and metadata.
However, when we centralized the metadata, some systems, like data quality, became workflows. There was no longer a need for separate systems. You could simply access the central metadata, run tests, and record the results. This greatly simplified the architecture. We are now trying to do the same thing. We want to transform standalone systems into workflows tied to metadata.
Data cost control, deletion, management, and other tasks can be automated within companies using APIs. Companies can build their own automation through workflows. Many manual tasks can be automated using APIs for specific purposes within a company.
On Prioritizing The Open-Source Roadmap

Community is our top priority. Based on past experiences, we understand that customers hold great importance. Listening to customers and their feedback is crucial. Our community has played a significant role in contributing to this project.
Community involvement goes beyond just coding. They also help with testing, provide feedback, and request new features. This input is precious to us. While we have monthly feature releases, we also frequently release smaller updates based on community requests. If a feature is requested by the community, we prioritize it and deliver it to them.
Additionally, we focus on avoiding unnecessary complexity. If a feature only benefits a small percentage of users but makes things more complicated for the majority, we make sure to provide it in a pluggable way. This allows users to have those features without negatively impacting the rest of the community.
We have a roadmap in place and actively seek feedback for it. We also receive daily feedback on what is working, what needs clarification, and what features are needed. We constantly prioritize based on this feedback.
On The Architecture of OpenMetadata
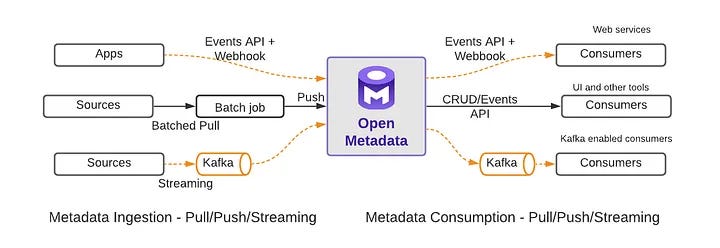
Let's start with the architectural principles. Why did we not open-source Uber's project instead? We decided to build from the ground up. The first principle is modularity. In many companies, different organizations have different ownership when a project is built correctly. They use different architectural patterns.
However, these approaches do not work for everyone. That's why we decided to build our project from scratch. This means that our frameworks and technologies must be open source. They must have a thriving community to continuously progress. We have built our project on top of these open technologies, instead of using proprietary ones like a REST framework or a schema modeling language.
The second principle is simplicity. From past experience, I have learned that things with the least number of moving parts are easier to operationalize and more reliable. Therefore, our architecture has minimal components. We have a single metadata store and use Postgres or MySQL as the system of record for storing data. We also utilize Elasticsearch for indexing, which is not a system of record. Additionally, we have adopted open frameworks and favor push over pull.
I want to address a confusion that arose from another blog. For example, the Data Hub project has Kafka as a dependency underneath, which we intentionally avoided. Operationalizing the metadata system is simpler compared to operationalizing Kafka.
We have not made Kafka a core dependency; just because we have Kafka does not mean it has become a push system. Most metadata sources, such as databases, do not automatically publish events. You need to pull metadata from them. While you can pull data from these sources and put it on Kafka for consumption, this is more suitable for scenarios with multiple subscribers consuming metadata from Kafka, not just a catalog system.
This approach has its benefits in a large company. However, our current system supports both pull and push. There is no push-only system. In some cases, it may involve a pull, push, pull, push process, which complicates the flow. We could have kept it simpler with just a pull, but various factors led to this more complex approach.
We support various options depending on the source and its capabilities. You can pull metadata, push metadata, or use our client libraries for specific changes. All options are available to cater to different needs.
On Co-Founding Collate

Our immediate focus should be on making open metadata the best community and project, with the goal of solving the metadata problem once and for all. We have a metadata system with various connectors that collect and centralize metadata.
We believe that once this metadata is stored centrally and accessible through APIs, a lot of innovation can take place. Our open-source efforts are focused on building metadata applications, specifically in data discovery, collaboration, and quality. These three aspects showcase the power of metadata for the future.
Looking ahead, we envision metadata not only being limited to discovery but also incorporating collaboration. We strongly believe in the potential for automation, such as moving unused data from hot to cold tiers. All of these tasks revolve around workflows and automation related to metadata.
We aim to build extensive automation to eliminate manual tasks and improve productivity. This will remain a key focus for Collate.
On Hiring
Hiring is one of the toughest challenges for startup founders, especially when our network consists primarily of individuals from larger companies who may not have a startup mindset.
Fortunately, being an open-source project has been advantageous for us. We have attracted talented individuals who are passionate about our project and willingly contribute their time on weekends and nights. This approach has helped us recruit some of our initial employees. Additionally, when we attract exceptional talent, they often recommend other great candidates from their network, including friends and former colleagues.
Traditional technical interviews can be hit or miss. Asking algorithmic questions may not always accurately assess a candidate's capabilities. To overcome this, we now assign a feature or bug from our project during interviews and observe how candidates perform. This approach has yielded positive results.

Our culture is characterized by a flat hierarchy as a fully remote company. Instead, we aim to have no managers and seek self-driven leaders who understand company priorities and make independent decisions.
Transparency is vital to our culture. We record and share all meetings and related information with everyone, reducing the pressure to attend every meeting while ensuring everyone has access to necessary information.
With minimal meetings and a strong emphasis on technical expertise, we strive to create a company where everyone is a leader.
On Fundraising
One of the reasons why we chose Unusual Ventures is because we had a similar hypothesis. They have conducted market research, and our proposal aligns well with their findings. So, that chemistry is super important. It's crucial to have a shared understanding of the market, technology, trends, and the company's direction.
Another essential factor to consider is talking to other people funded by that specific VC. Not every VC will be the right fit for your culture or philosophy, so it's important to speak with others who have received funding to assess whether there is a cultural fit.






