



The 101st episode of Datacast is my conversation with Tarush Aggarwal - the Founder and CEO of 5x, the modern data stack as a managed data service. He is one of the leading experts in leveraging data for exponential growth, with over ten years of experience in the field.
Our wide-ranging conversation touches on his college experience at Carnegie Mellon University, his time at Salesforce as the first data engineer, lessons learned from building and managing a data team as a Data Manager at Wyng, his leadership role at WeWork scaling the data team and establishing the operations in the Chinese market, his current journey with 5x building the app store for the modern data stack, and much more.
Please enjoy my conversation with Tarush!
Show Notes
(02:24) Tarush shared his upbringing in India and his decision to study abroad in the US.
(03:51) Tarush walked through his college experience studying Computer Engineering at Carnegie Mellon University.
(06:24) Tarush described the non-existent state of data infrastructure at Salesforce when he joined as the first data engineer in 2012.
(11:21) Tarush went over his contribution to the automation and benchmarking frameworks over his tenure at Salesforce.
(15:50) Tarush recalled lessons learned from building and managing a data team as a Data Manager at Wyng.
(19:54) Tarush explained how a data team can serve other functional units more efficiently.
(22:37) Tarush elaborated on his decision to adopt Looker for Wyng's Business Intelligence needs.
(26:30) Tarush talked about his decision to join WeWork as their Director of Data Engineering in 2016.
(30:39) Tarush went over the origin and evolution of Marquez - WeWork’s first open-source project around data lineage - during his time as the director of WeWork’s Data Platform team.
(33:49) Tarush highlighted the main challenges of building an internal data platform.
(35:43) Tarush recalled his move to China to help establish WeWork’s Asia operations and focus on the hyper-growing Chinese market.
(39:01) Tarush shared the founding story of 5x during his sabbatical in 2020.
(42:39) Tarush explained the industry’s need for a managed data stack.
(45:20) Tarush went over 5x’s process of sourcing, interviewing, and onboarding data engineers who are pre-trained on the modern data stack.
(48:37) Tarush talked about finding the right vendors that make up the modern data stack to partner with.
(50:06) Tarush walked through his production process to put together a lot of good videos to explain what 5x does and raise awareness about the company.
(51:52) Closing segment.
Tarush's Contact Info
5x Resources
Mentioned Content
People
George Fraser and Taylor Brown (Founders of Fivetran)
Prukalpa Sankar (Co-Founder and CEO of Atlan)
Frank Slootman (CEO and Chairman of Snowflake)
Books
Stealing Fire (by Steven Kotler and Jamie Wheal)
The 5 AM Club (by Robin Sharma)
About the show
Datacast features long-form, in-depth conversations with practitioners and researchers in the data community to walk through their professional journeys and unpack the lessons learned along the way. I invite guests coming from a wide range of career paths — from scientists and analysts to founders and investors — to analyze the case for using data in the real world and extract their mental models (“the WHY and the HOW”) behind their pursuits. Hopefully, these conversations can serve as valuable tools for early-stage data professionals as they navigate their own careers in the exciting data universe.
Datacast is produced and edited by James Le. For inquiries about sponsoring the podcast, email khanhle.1013@gmail.com.
Subscribe by searching for Datacast wherever you get podcasts, or click one of the links below:
If you’re new, see the podcast homepage for the most recent episodes to listen to, or browse the full guest list.


Key Takeaways
Here are the highlights from my conversation with Tarush:
On His Upbringing
I grew up in a very entrepreneurial family in India. My mother had a very early e-commerce business, so I was exposed to tech and computer science at an early age. I remember that we were given our books in advance on the first day of 9th grade. I picked up a computer science book and read half of it before the end of the day. I had never been so passionate and excited about something up to that point. It was clear that my interest lies in computer science and software.
My parents were able to send me abroad. In the early 2000s, India's Computer Science educational system was less advanced than in America. The decision to go abroad and study Computer Science was easy; fortunately, my parents could afford to send me there.
On His College Experience at Carnegie Mellon University
Growing up in India, I lived in a very sheltered environment. When I finally went abroad, I had all this freedom, which went over my head, and I had no idea how to manage it. I was the worst student ever, and I probably only graduated by the sheer combination of dumb luck and the fact that I had coded for a few thousand hours before getting to college.

The valuable thing that I did in college was I worked on a research project in the Parallel Data Lab. Google had given CMU a bunch of servers, and we had one of the first Hadoop instances at CMU. I worked on a project where we were working with astronomers to build a way of indexing the stars in the sky and cataloging them. In fact, the app SkyMap on Android used the same algorithm we developed in 2008.
On Joining Salesforce as The First Data Engineer
I joined Salesforce as a performance engineer since there was no data engineering title back in 2011 (when I was out of college). I quickly realized that software engineering performance was not my cup of tea. Although obviously valuable, working on a small feature in a small product was not something I found interesting.
At that time, no one was talking about data. I met a product manager who was interested in looking at log files and extracting metrics from them. That sounded very interesting because, suddenly, we could aggregate these metrics and figure out how customers were using the product. As simple as that sounds today, that was not very simple back then. Log files were zipped up on an app server and shifted (the next day) to a central hub. We had to unzip them, move them over to HDFS, and run a big job on top of it.

This process was very prone to failure. If something failed, somebody would literally have to re-put a disk somewhere. That was very different from what we have today, where we can install a frontend tracking tool (Mixpanel, Amplitude, or Heap) and slice & dice the analytics on a web interface.
Toward the end of my four years at Salesforce, we got our first Cloudera Hadoop cluster. At that time, we moved over to Hive as well. Overall, data was in its early days, and data engineering & analytics were not real job descriptions.
On The Automation Framework at Salesforce
At that point, we had a bunch of data scientists embedded in each business unit of Salesforce. The business leaders want to figure out what is happening, how customers use the features, and what they should focus more/less on. The data scientists needed to be able to answer these questions dynamically. The old way of doing it is that: they would have to go to someone on the Analytics team for help. That person would load the data into Splunk, write some queries, and write some statements to extract a CSV file. The scientist would play around with the CSV file to figure out week-by-week and month-by-month data. This process was very manual.
My team extracted these logs, put them inside HDFS, and ran a Pig script against them to extract what we wanted. The automation framework allowed these data scientists to easily define what they wanted to extract using an XML file. The framework would automatically generate Pig scripts which would take this instruction set, run it against the Hadoop cluster, pull metrics out, and push them back inside Hadoop - where they can consume. Suddenly, we push the power of processing back to the data scientists. There is no ad-hoc manual step in between.
The business units did not have to wait an entire month to get analytics. They were now able to do it in a week. It sounds ancient in today's lingo, but removing manual parts of that ad-hoc process and getting it down to a week was a big success at that point.
Another benefit of this automation framework is that we could build dependencies on top of it, not just for data going into HDFS but running ETL jobs or updating dashboards. Automation does not end with data extraction. It can go all the way up to data reporting. This was the first time that thought and possibility entered my head. Salesforce was still a massive company at that point, and it took time to try new things. Toward the end, I wanted to know if we could extend this automation idea further along the way and whether there is an opportunity to do that for a company of a smaller size.
On Building The Data Team at Wyng
Wyng was generating user content. Let's say Pepsi is trying to launch a hashtag campaign all over the web. Wyng could pull that data, figure out the high-quality data, and give it back to Pepsi such that Pepsi could use it inside their new campaigns. User-generated content was going to drive a lot more engagement than typical ads. Being able to pull data from different data sources, analyze it, and find the best one was an interesting problem.
This opportunity was very different from Salesforce - moving from one of the biggest companies in the Bay Area to a 150-person company with a tech team of 30-40 people and a 1-person data team. There was no reporting, and everything was manually extracted. It was an opportunity for me to take lessons from Salesforce and apply them to see if they work in the real world.

One of the first things we did was adopting Looker. Building out self-service reporting is what I always visualized as the end piece of the automation flow so that anyone can answer their own questions.
Another thing we started doing was building a modeling layer. After taking data from your raw sources, instead of having your self-service reporting built on top of the raw data, can you call a data model? We built a few data models across sales, marketing, and product, allowing us to be efficient and nimble. We could change metric exchange reporting and move much quicker than the old way. We did not have dbt then, so we used a homegrown scheduler I had written in a few hours and deployed it on AWS.
The experience at Wyng was fun and hacky. At that point, I had made a lot of mistakes building and managing data teams and figured out what not to do if I did it again. Two years later, I was ready to look for the next thing. I thought I would go back to San Francisco, but all of a sudden, WeWork showed up.
On Joining WeWork
The first time I went to the WeWork HQ office, I felt this electric energy I had never felt anywhere else. I remember going for dinner with the CTO, and as he convinced me to join at that point, I knew I would join no matter what he would pay me. It was one of the easiest decisions in the world.
In the last decade, many traditional industries have been disrupted. Taxis had been disrupted by Uber. Music had been disrupted by Spotify. Real estate was one of the remaining few places to be disrupted. WeWork was offering that solution.

They were still relatively small then. The tech team had about 80-90 people. The entire data team had two data engineers, one BI person, and one data scientist. It was very fun going in there. Being part of that exponential growth was the journey of a lifetime that I am extremely grateful for. I learned from it the culture of being extremely together for a long time. We would work really hard during the day, but after work, we would hang out with folks inside WeWork and talk about WeWork at the time. It is an all-encompassing culture, but one that's very much in their DNA.
As we grew quickly, how could we hyper-grow at that speed? The data team went from 5 people when I joined to 100+ people three years later. We did that by opening offices in different locations and attracting talent from other places. We funded a bunch of conferences and acquire-hired other startups. It was much easier to hire back then as the WeWork story was starting to become more mainstream.
On The Evolution of WeWork's Data Platform
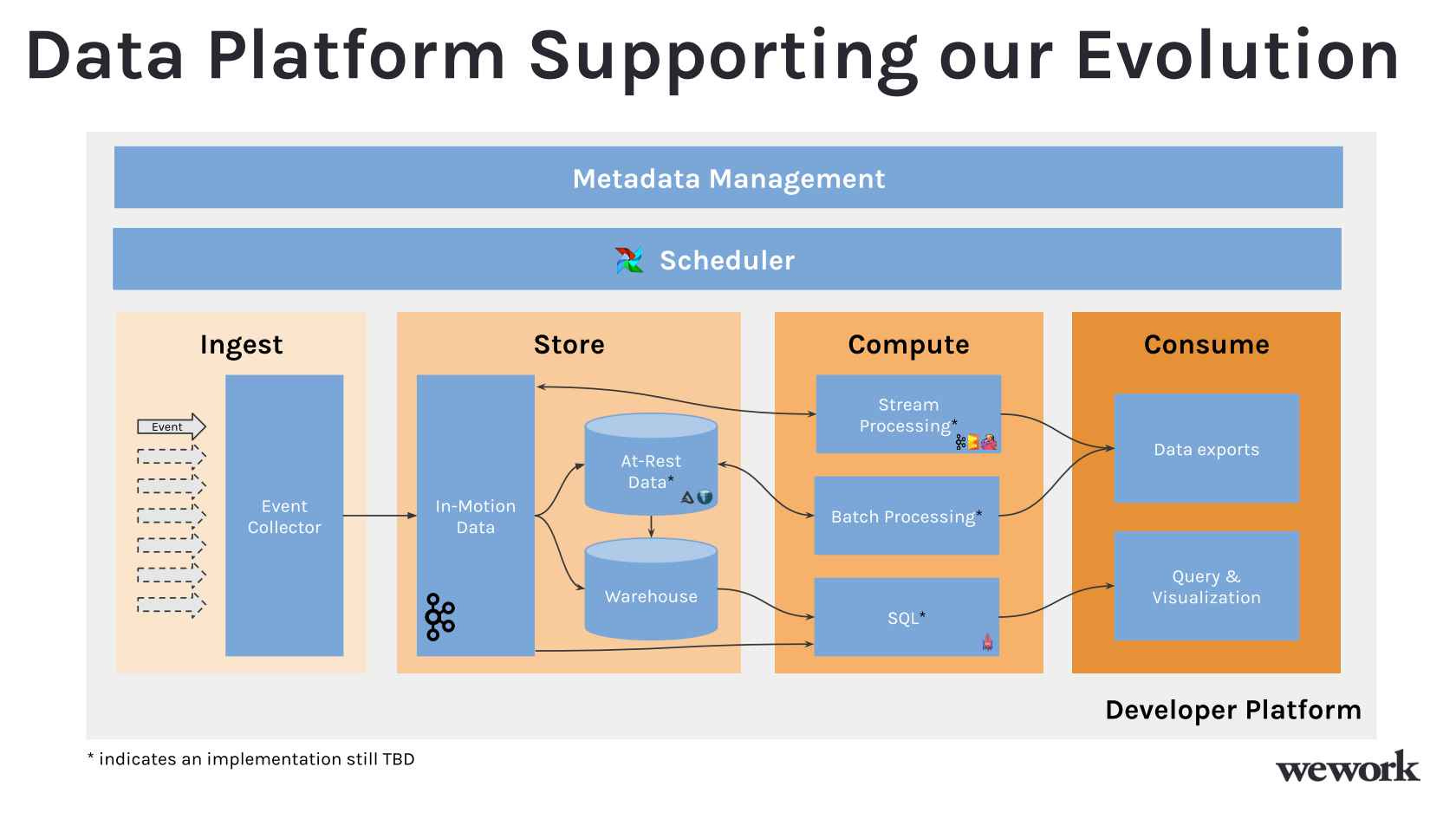
Initially, I was focused on the data engineering side of things. As the data engineering team started to scale, we found a gap in the data platform needs, which include ingestion, storage, compute, and other layers in our pipeline. WeWork's ecosystem was diverse: we had different types of data, and we had teams focused on digital experience, machine learning, physical construction, and IoT devices. We did not intend to build a one-size-fits-all platform.
Today, the data warehouse has become the default storage layer. Back then, we intended to have flat files, construct batch and real-time processing pipelines, or use a data warehouse for analytical purposes. These are non-trivial problems around the scope of our data platform. In reality, we needed pieces of everything. The idea was to build a data platform team that could eventually support all use cases.
On Establishing WeWork's Asia Operations in China
I was burned out during my time at WeWork. I actually was going to leave to write a book on data and take a sabbatical. However, a dear friend of mine convinced me over drinks that he was going to China and needed to ask me questions about data. A few drinks later, we decided that, instead of quitting, I would go with him to China to do this together. It ended up being a journey of a lifetime. I had never even visited China previously, so that happened very quickly, and I enjoyed every second of it.
For those who do not know, there are two Internets in the world - a global Internet and a Chinese Internet. They do not speak to each other. In a different way, there has been no successful American company just taking the American stack and deploying it in China. The successful ones have actually rebuilt a version of the platform on the Chinese cloud, either Alibaba or Tencent cloud. It was an opportunity for us to do exactly that for WeWork.

A memorable thing about building in China is the concept of "China speed" - how to build something four times faster with quality in mind? I remember it took a global team about a year and a half to build the WeWork app, while the China team did it in four months. They built their own version of the WeWork app with the entire feature set much faster and equally high quality.
Chinese engineers are just hungry and looking to be on the map. They would come into the office on the weekend. I might have left my laptop, returned to pick it up, and seen the engineers working there all night. You might have heard of the China 9-9-6 culture: working 9 AM to 9 PM for 6 days a week. In America, it is the 9-5-5 culture: working 9 AM to 5 PM for 5 days a week. We tried to level set for a 9-5-5 culture when we went there. In reality, many engineers would ask for extra work at the end of 9-5-5 because they were looking to work harder and find success.
On Founding 5x

I took some time off and went on a 10-day vacation to Bali. That happened to be day one of COVID, and China shut down so quickly. I never got to pack my apartment, so I moved to Bali with a small handbag and made it home. I decided to leave WeWork and took a few months off indefinitely.
I started a company called 5x Wellness, which built a segmentation product for wellness companies to personalize different audience segments. That did not go anywhere. I would start taking everything within my career in the data space and teaching companies how to structure data teams, the modern data stack, how to set it up, etc. I did that for six months and literally sold four courses. I was trying my level best to build a business out of this, and I was failing miserably at it.
I happened to take a trip to Jakarta and met a friend from college. He introduced me to one of his buddies, a serial entrepreneur named Karan. Karan was just coming out of his previous startup. He loved what I was building but said he would not get involved unless we spoke to 100 companies. We flew back to Bali and spoke to 13 companies. 12 of them had a data problem, so we did not speak to any more companies.

Karan then gave me one piece of advice: "No one wants to learn from you. Everyone wants you to do it for them. To succeed in this, you need to find a way of doing it without being a consultant."
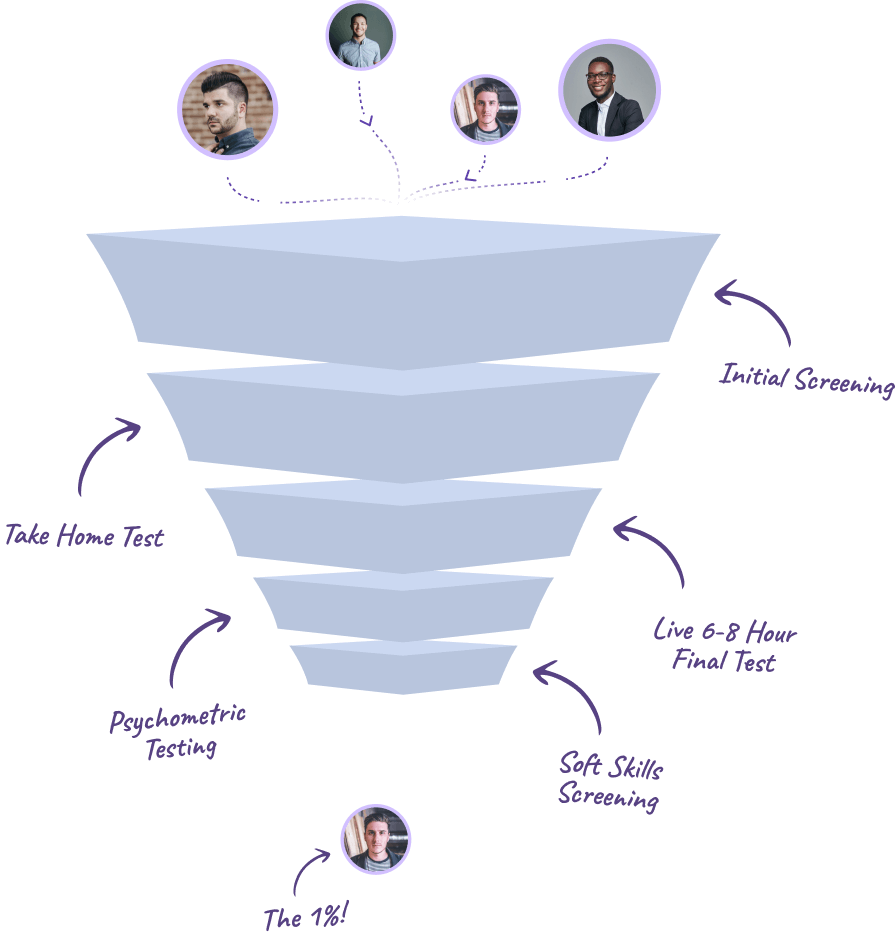
We started rebuilding the interview process. One weekend, we had 50 people who applied, and we hired 5 of them. They had to complete an online test: 6-hour of doing data ingestion, structuring, and reporting - daily tasks of a data engineer. After hiring these people, we taught them our program instead of teaching it to companies. Then we took these people and embedded them into companies. We ran this playbook, which turned out much better than we thought. That is how 5x started.
From there, we had the idea that: all these companies need a data platform, so can we be a single platform that provides the modern data stack? They can pick and choose vendors, and our platform stitches things together. On top of that, we also provide the talent layer.
On The Industry Need for A Managed Data Stack
The Modern Data Stack movement will allow all companies in the next few years to figure out questions like: Where are the customers coming from across campaigns? What are the different segments with customer lifetime value with engagement? How do you optimize operations? How do you automate financial dashboards? Who are your best sales reps? These are the types of questions all companies will need to answer.
When we think about answering these questions, the old way of doing it (like what we did at Wyng and Salesforce) is no longer applicable. The average company today has gotten between 10 to 12 different data services. You need to be able to ingest, store, model, structure, and report the data. Once it gets to advanced decision-making, you want to be able to do A/B testing or machine learning. These different use cases are what we call the Modern Data Stack. Unfortunately, each use case is done by a separate, high-valuation company. To set this whole stack up, you must find 10 different contracts and spend 6 months stitching them together.
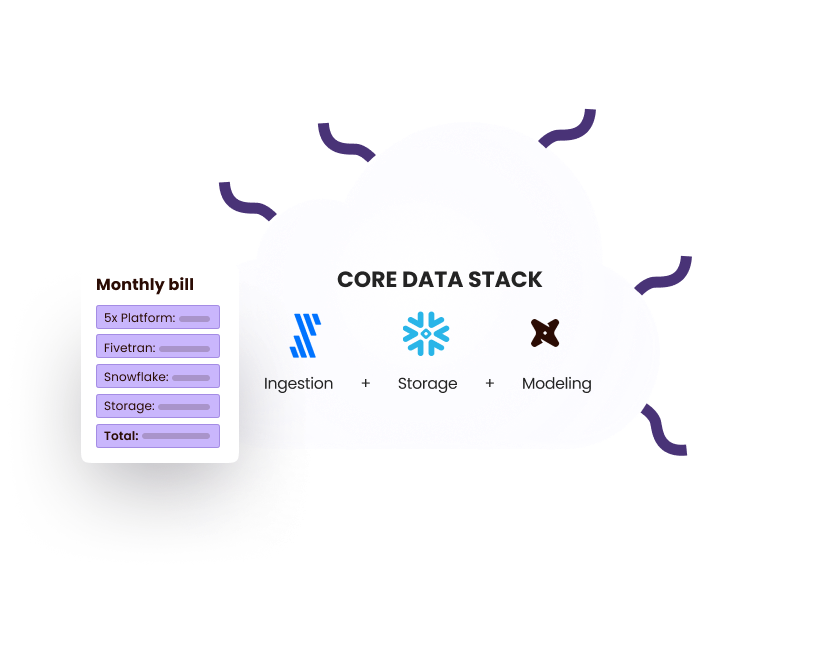
Simply put, 5x provides a modern data stack out of the box. Unless you are the 10% of big companies like the FAANG, the remaining 90% of companies are just doing it inefficiently. Do you want to spend an additional $100,000 and 6 months longer to do it (and there is still a chance of doing it incorrectly), or do you want something out of the box and focus on the business value? That is fundamentally why 5x exists in order to become the de facto platform behind the modern data stack for 90% of companies.
On Training Data Engineers
We first built this process around India. We were doing about 500 interviews a week, so we had about 90% of the process automated. There is a take-home test, there is a 6-hour practical test, there is a live interview with one of our engineers, there is psychometric testing, and there is the offer. It is quite an intensive interview process. We are now doing it in 9 countries - expanding from India to South America, Southeast Asia, and parts of Africa. We are building a global task force, essentially.
Besides having dedicated engineers embedded into companies, we have this new concept called Engineering Pod. We take three engineers and put them together on the pod, which can support multiple companies. A pod is really a very elastic supply of data engineering talent. So a company can get access to a pod, which comes with (hypothetically) 30 engineering hours of support for a week. The company can add or subtract a pod if it needs to scale up or down. Pods are infinitely customizable. They can have 24-hour support with pods worldwide - whether junior engineers for more cost-effectiveness or senior engineers for more critical architectural fixes.

With the pod model, we really focus on adding true business value in an elastic manner. This is based on the idea that: we are moving into an age where companies care about the output, not how the work gets done. A big problem in engineering has always been that: hiring, managing, and deploying engineers often do not match the speed of what a company needs. A company might need something now, but it will take three months to hire someone and get them started. They will never match the supply-and-demand needs with this model. 5x is building one of the first true elastic models to supply data engineering talent.
On Partnering With MDS Vendors

As more and more categories are added to the Modern Data Stack, what is happening is that in some core categories like ingestion, warehousing, modeling, and BI, best-in-class vendors are becoming more established - such as Fivetran, Snowflake, and dbt. BI and front-end collections may have more options. Additional categories like metadata, reverse ETL, data mesh, and metrics store will appear as time passes. For us at 5x, we are figuring out which providers in these categories are going in the direction we believe the modern data stack is going. Then we plan to partner with these providers.
In reality, we are not trying to offer just one partner for like metadata or reverse ETL. Any of these providers should be able to offer their services and fully integrate into 5x. Our vision is to create an app store for the modern data stack.






