




The 123rd episode of Datacast is my conversation with Itai Bar Sinai - the Chief Product Officer and co-founder at Mona Labs, the leading AI monitoring intelligence company.
Our wide-ranging conversation touches on his education in Math and Computer Science; his early career as a software engineer at Google; his time as an AI consultant; his current journey with Mona Labs building an end-to-end AI monitoring platform; perspectives on monitoring strategy and product-oriented data science; lessons learned finding engineering talent and design partners; the thriving ML community in Israel; and much more.
Please enjoy my conversation with Itai!
Show Notes
(01:46) Itai reflected on his education at The Hebrew University of Jerusalem, studying Math and Computer Science.
(04:18) Itai walked through his time as a software engineer at Google working in Google Trends.
(06:56) Itai emphasized the importance of a software checklist within Google's engineering culture.
(08:55) Itai explained how he became fascinated with AI/ML engineering.
(10:31) Itai touched on his period working as an AI consultant.
(13:28) Itai talked about his side hustle as a co-owner of Lia's Kitchen, a 100% vegan restaurant in Berlin.
(16:13) Itai shared the founding story of Mona Labs, whose mission is to make AI and machine learning impactful, effective, reliable, and safe for fast-growth teams and businesses.
(21:25) Itai unpacked the architecture overview of the Mona monitoring platform.
(24:50) Itai talked about the early days of Mona finding design partners.
(27:15) Itai dissected his perspective on a comprehensive monitoring strategy.
(31:42) Itai explained why the secret to comprehensive monitoring lies in granular tracking and avoiding noise.
(38:35) Itai explained how Mona can support real-time monitoring across the layers of the platform.
(43:18) Itai mentioned the integration with New Relic to display the variability of use cases for Mona.
(46:08) Itai discussed the shift for data science teams from being research-oriented to product-oriented.
(51:03) Itai provided four tactics for data science teams to become "product-oriented."
(58:04) Itai shared valuable hiring lessons to attract the right people who are excited about the mission of Mona Labs.
(01:01:46) Itai provided his mental model for finding exceptional engineering talent.
(01:03:38) Itai brought up again the importance of finding lighthouse customers.
(01:05:46) Itai gave his thoughts on building the product to satisfy different customer needs.
(01:07:55) Itai described the thriving ML engineering community in Israel.
(01:09:42) Closing thoughts
Itai's Contact Info
Mona Labs' Resources
Mentioned Content
Blog Posts and Talks
We are building Mona to bring ML observability to production AI
The secret to successful AI monitoring: Get granular, but avoid noise
Taking AI from good to great by understanding it in the real world (June 2022)
Common pitfalls to avoid when evaluating an ML monitoring solution
Introducing automated exploratory data analysis powered by Mona
Best practices for setting up monitoring operations for your AI team
Overcoming cultural shifts from data science to prompt engineering
People
Goku Mohandas (Creator of Made With ML)
Ville Tuulos (CEO and Co-Founder of Outerbounds)
Nimrod Tamir (CTO and Co-Founder of Mona Labs)
Notes
My conversation with Itai was recorded back in October 2022. Since then, Mona Labs has introduced a new self-service monitoring solution for GPT! Read Itai's blog post for the technical details.
About the show
Datacast features long-form, in-depth conversations with practitioners and researchers in the data community to walk through their professional journeys and unpack the lessons learned along the way. I invite guests coming from a wide range of career paths — from scientists and analysts to founders and investors — to analyze the case for using data in the real world and extract their mental models (“the WHY and the HOW”) behind their pursuits. Hopefully, these conversations can serve as valuable tools for early-stage data professionals as they navigate their own careers in the exciting data universe.
Datacast is produced and edited by James Le. For inquiries about sponsoring the podcast, email khanhle.1013@gmail.com.
Subscribe by searching for Datacast wherever you get podcasts, or click one of the links below:
If you’re new, see the podcast homepage for the most recent episodes to listen to, or browse the full guest list.
Key Takeaways
Here are the highlights from my conversation with Itai:
On His Education
I've been a geek since long before university. My parents are computer programmers and were among the first in Israel to pursue a computer science degree.
When I was six, my dad bought our first PC for our family house and taught me how to program in Basic. My first experience with the English language was actually with a programming language. As I grew up, I attended programming summer camps and eventually became an instructor at one.

Studying computer science was a natural path for me. Initially, I started studying both computer science and cognitive sciences, but after just one semester, it became apparent that math was my greater passion. So, I switched to computer science and math and completed my bachelor's degree at The Hebrew University of Jerusalem.
Most of my favorite classes were around algebra, including graph theory and topology. If I had continued academic studies, I would have pursued math, focusing on more abstract topics like algebra, topology, and others.
On His Time at Google

I started as an intern while still studying at university and eventually became a full-time employee, spending four years on the Google Trends team. For those unfamiliar, Google Trends is an analytics product that utilizes Google search and other data to show what people are searching for and what the world is thinking about, according to Google News. It's a democratization of Google's data, which makes it a highly recommended tool for anyone working with data.
One of the cool things about the Google Trends team is that it always acted like a startup within Google. This gave me the opportunity to work on a wide range of areas, from front-end client-side JavaScript and HTML to big data pipelines and machine learning operationalization within Google. The latter was interesting because it was done differently at Google, especially on the Trends team.
I worked on many different projects, but one that stands out was integrating Trends data into Google News. This created a feedback feature for journalists, allowing them to see how much interest there was in the topics they were writing about and how many articles had already been written on the same topic. This helped them balance their reporting according to the public's interest.
Working for such a big company on such a project was an extraordinary experience. For example, after the project went live and journalists started using it, I had the opportunity to visit the CNN newsroom in New York and see the product I built on the big screen in the middle of the newsroom. This is something that takes a long time to achieve when building a startup.
On Software Checklist

Google is an exciting place to work for an engineer like me. However, it's very different from earlier-stage companies. Whatever you want to push out has to go through a strong checklist. You have to make sure everything is fine before it's released. If something goes wrong later on, you need to have a plan on what to do about it. This inspired a lot of what we're doing now in Mona.
When you build something new, it's your responsibility to create a "cookbook" of what can go wrong because it will affect so many people and so much of the business. You need to think about what might go wrong and what needs to be done quickly to resolve the issue. You need to map out all those scenarios.
This kind of thinking isn't happening today in AI, but we will dive more deeply into it later.
On Getting Into Machine Learning
Initially, I focused on front-end and full-stack development, which usually involves simpler tasks, although not always. Gradually, I became more oriented toward back-end and big data.
Additionally, I focused on operationalizing machine learning within Google. Many pre-built models are already available, and the challenge was to determine how to use them effectively in my current projects.
What fascinated me was the seemingly magical aspect of machine learning. These models could provide a clear path forward when faced with a problem and lacking a clear solution. Of course, I came to understand that it was not actually magic, but this initial impression made machine learning very appealing to me.
As a result, I delved deeper into this field later in my career at Google.
On Being an AI Consultant
After leaving Google, I had a couple of side hustles. It was clear to me that I wanted to build my own projects from scratch. Working at Google was great, but I felt the need to create something of my own. One of the things I learned at Google was that I care about building things that are mine. Whenever I had the opportunity to create such a project within Google, it always felt the best to me. I knew I needed to do something with AI, so I focused on filling gaps in my knowledge and experience.
Firstly, I wanted to work as a data scientist and get much deeper into AI from the research or data science side. Additionally, I wanted to understand how things work in early-stage startups, as it is very different from what you encounter when working at a large corporation like Google.
To achieve this, I worked a couple of jobs, such as building a computer vision model from scratch to understand what's going on in a driver's dashboard for a smart fueling app.
I also worked as a consultant for a small Israeli AI-centric VC, where I met different early-stage AI companies in Israel and better understood how the business side of things works in those areas. This experience was also beneficial in my current endeavors.
On Co-Owning Lia's Kitchen

After leaving Google, I worked on a couple of side hustles, including building a few consumer products like a small travel app. Although they had mild success, it was difficult to make money from them.
But it wasn't all about that. I also dreamed of opening a restaurant with a couple of friends. We would meet weekly for dinner, and one of my friends was a great cook. We discussed opening a restaurant in Berlin, where we all wanted to go. I had some experience in Germany from a foreign exchange student program and knew I wanted to go back.
My friend finished studying and moved to Berlin. A year later, he called me and said, "I moved here. We always said we were going to open this restaurant. So what's up? I did my part. Why aren't you here?" I had to fly over there and help out.
To be honest, it was a side hustle for me. My friend and another friend built everything, and I was more of a silent partner who helped ramp things up. I spent a year in Berlin helping with the restaurant while working on other projects. n. I highly recommend checking it out if you're traveling to or living in Berlin.
However, I wouldn't recommend starting a restaurant. It's harder than starting a startup and a very difficult thing to do.
On Co-Founding Mona Labs
Nimrod was my boss back at Google, serving as the global engineering lead of Google Trends. We left Google around the same time and kept in touch as friends. A couple of years later, around April 2018, we met and discovered that we were both seeking the next big thing.
At the time, I was a consultant, and Nimrod was a VP of engineering at a later-stage AI startup. He reached out to his roommate and best friend from university, and we all came together to find something big to do with AI. We started ideating, and Nimoy proposed the idea of a monitoring platform. We all had experience with productionizing AI, and the concept resonated with us.
Nimrod had struggled to trust the AI system at his previous company and found it difficult to sleep well at night, knowing that anything could go wrong, and it was impossible to predict when it might happen. He attempted to solve this issue in-house, but it proved very challenging and resulted in suboptimal outcomes. We conducted further market research and found design partners to work with before finalizing our decision.
It became clear to us that monitoring was a significant part of the infrastructure gap in the AI industry. AI was becoming ubiquitous, but the infrastructure hadn't evolved as quickly as the research and use cases. By creating a monitoring platform, we sought to address this need and be at the forefront of the AI industry's growth.
On The Co-Founder Relationships

We knew that we were a good fit to work together as founders. Nimrod and I had worked together for four years at Google and had a great working relationship. We shared the same style, culture, and goals. Yotam, our CEO and co-founder, was Nimrod's college roommate, and they also had a great relationship based on shared values and culture.
Although Yotam lives in the U.S., we spent a couple of months together during ideation and working on some projects. We even did a whole week workshop where we built different scenarios for the startup to see if we were thinking about the same things and aligned in our interests and goals. We found that we were, and although nothing is ever perfect, we didn't encounter any major issues.
Today, four years into this, Yotam and I are best friends and have a great working relationship. We're all good friends now; our shared values and culture have helped us build a successful startup.
On The Mona Monitoring Platform

Mona has four main layers, starting with the data layer that allows you to easily collect relevant data from various sources. This includes model inputs and outputs, business metadata, feedback, manual labeling, and technical metadata. This layer creates a monitoring data set, which is a schema that defines the metrics and fields you want to track.
The visualization layer provides analytical and exploratory capabilities on top of the monitoring data set. This includes dashboarding, report creation, exploration, hypothesis testing, root cause analysis, and troubleshooting. Mona also has investigative tools available through a dashboard or programmatic API.
The intelligence layer is perhaps the most important and differentiated layer. Its job is to find where your system underperforms, has drifting behavior, or sudden changes you didn't expect. It shows you where this happens as early as possible with full context, allowing you to resolve the issue quickly.
Finally, the operational layer connects back to your workflows and ensures the right person is alerted at the right time about the right issue. It connects to your messaging and ticketing systems, allowing you to track and resolve issues over time.
Mona is an end-to-end monitoring platform that provides a full solution, covering everything relevant to the monitoring lifecycle. While some configuration and tailoring may be required for your specific use case, Mona's architecture is designed to address all your monitoring needs.
On Finding Design Partners

We started early on by finding design partners before building any architecture. We intentionally sought out late-stage startups that were AI-centric. We realized early on that these were the thought leaders. For example, Gong.io is one of our customers and has one of the most advanced AI teams available. These are the teams that are paving the way for the future of big corporations.
Instead of focusing on big deals initially, we prioritized finding companies that best understood the problem. We found a couple of these companies that shared our vision regarding this pain and need and started working with them. We researched and understood why their pain points existed and how they would use our solutions.
We invented something new from scratch. No other company had this line item in their P&L. No company had already paid for monitoring specifically for their AI. These companies had attempted to build something in-house and got suboptimal results. We learned from their pain points and built the best solution possible.
On Monitoring Strategy
The best place to start is by asking what you mean by monitoring. To me, it's still unclear how different people interpret this question. Some say they want a dashboard to monitor how things work and their features are distributed. Others say they need to troubleshoot issues when someone reports a problem. Unfortunately, many AI systems in production are not adequately monitored, and the first person to notice an issue is often a business stakeholder, whether internal or external, who calls with a complaint.
This reactive monitoring approach can damage business KPIs and lead to firefighting. The goal of monitoring should be to detect and resolve issues before they impact business KPIs. Instead of waiting for customer complaints, monitoring should be proactive.
This is why we invested in an intelligence layer that can detect issues early and alert you before they impact your business. To achieve this, you must collect all data relevant to your model, not just model telemetry but also data outside the model scope. You need to be able to explore this data easily and quickly and have a proactive automatic mechanism that alerts you to issues. And, of course, you must be able to act on these alerts.
These are the key steps in monitoring AI. While they may seem abstract and zoomed out, they are essential to ensuring the success of AI systems in production.
On Granular Tracking and Avoiding Noise
That's a great question, and it's the perfect segue to the discussion about our intelligence layer and how it proactively alerts you. But how does it do that? Let me tell you a story about granular monitoring using an example.
Imagine you have a fraud detection model that runs on top of bank transactions. This model predicts whether a transaction is fraudulent by utilizing features derived from different data sources. Some of these features are derived from data saved on cookies in the customer's browser.
Now, let's say Google releases a new Chrome version in beta that changes the policies for how cookies can be read or saved. As a result, some of the features relying on cookie data may break, causing incorrect numbers or nulls. This may go unnoticed if the traffic from this new version is only a small percentage of the total traffic. However, this percentage may increase significantly in a few months, causing business to suffer and customer complaints to rise.

To detect these kinds of issues, you need a mechanism that can automatically detect specific segments that are behaving differently. This is where our intelligence layer comes in. The insight generator at the center of the layer searches all different business dimensions, such as browser version and device, to find specific segments with anomalous behavior and alert you even if it's only affecting a small percentage of your data.
However, searching everywhere may get a lot of noise, which is even worse than not monitoring at all. To avoid this, our system finds the root cause of the problem and alerts you once, along with all the other symptoms of the same problem, so you know exactly what to fix.
In summary, granular monitoring is crucial for detecting issues and preventing businesses from suffering.
On Real-Time Monitoring
Mona's data layer is a real-time data layer that provides customers with solutions for both streaming and batch processes in parallel. Ingestion is real-time, with different data logging endpoints for batch and real-time processes. This ensures that a large batch of data does not block real-time processes. Higher-priority processes are monitored in real-time and given layered priority to ensure that lower-priority data does not disrupt high-priority real-time monitoring.

The insights generator allows users to identify specific problematic segments in real-time systems. While it may take longer to detect smaller issues, the system is highly configurable to deliver highly granular insights once a day and big insights every 15 minutes. Mona's design is highly flexible, accommodating different use cases, such as computer vision in batch processes, e-commerce, audio analysis, and government agencies.
Mona started with three or four design partners and now has a two-digit number of customers, all of whom use the same software version. Mona's backend knows how to treat different data priorities to ensure that lower-priority data does not disrupt high-priority real-time monitoring. The system is highly configurable to meet the needs of different use cases and monitor for different types of alerts, including manual labeling and third-party data sources.
On Integration with New Relic
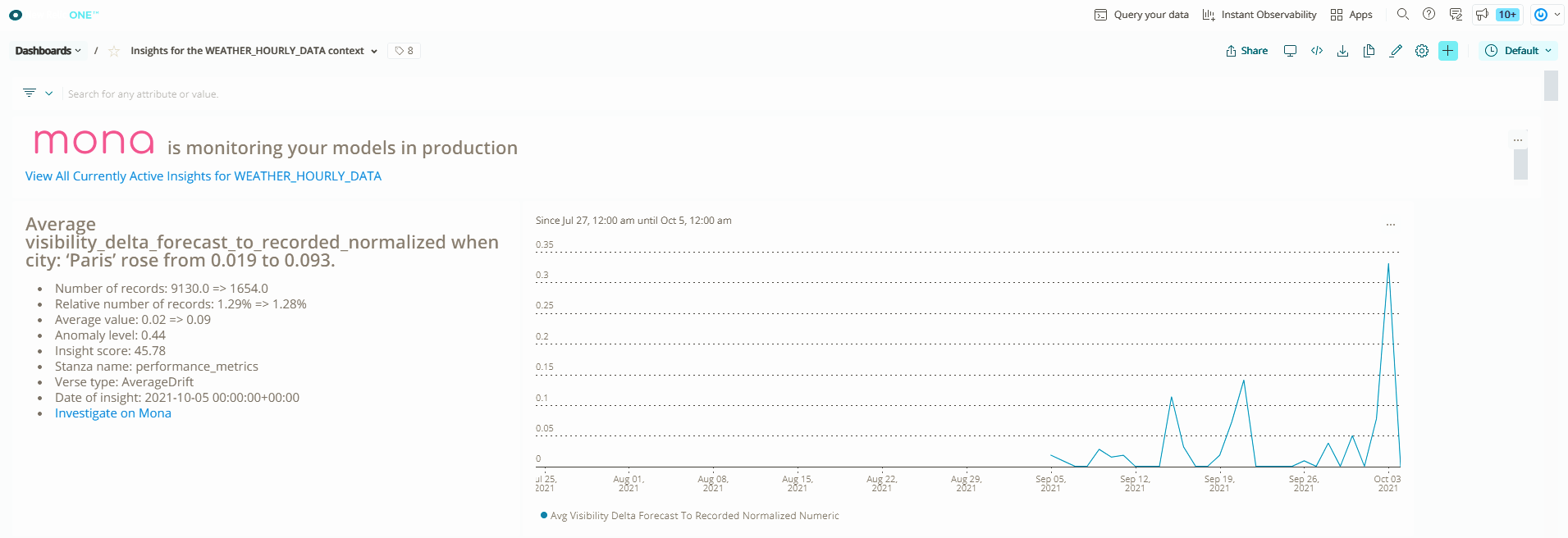
I find the integration's most interesting aspect to be the discussion point it raises about the variability in use cases, tax requirements, and necessary needs. Additionally, the organizational structure in different organizations can impact who is in charge of what. The Mona-New Relic integration allows DevOps- and production-oriented organizations to take more responsibility in AI.
Connecting Mona to New Relic provides visibility into the AI system for DevOps personnel, who can provide a first response in case of issues. Some companies build an internal production-oriented function within their data science team, with a weekly on-call rotation for data scientists to address issues that may be too specialized for DevOps.
The question of who will be in charge of what in AI production remains open, and there are different theories about how this will evolve.
On Product-Oriented AI
Product-oriented AI is a paradigm that has been discussed a lot lately. Traditionally, the data scientist's job has been completely research-oriented. Even today, if you search for "data scientist job" on Google, you'll see that their job is usually defined as understanding a business problem, collecting and preparing a dataset, training, testing, and deploying a model, with the model being the end product of their job.
This traditional approach causes a lack of clarity regarding who owns the model once it's in production, leading to problems such as monitoring by customer complaints and no one being accountable for the model. This makes AI a high-risk investment and causes frustration among business stakeholders who spend a lot of money on it.
To address these issues, there is a shift towards becoming more product-oriented. This means that the model is no longer the end product but rather the first step in an ongoing operational process that needs to be taken care of. The real test of the model is how it functions with regard to the actual business that it's trying to serve or the business KPIs.
The goal is to attend to and resolve issues before they hurt the business, so business stakeholders will trust AI. We are defining and pushing this paradigm shift, and when we work with customers, we focus on helping them become product-oriented in their thinking of AI. Monitoring is a central tool in achieving this goal.
On How To Be "Product-Oriented"

Number one, the most important tactic – and the most important thing you can do – if you want to become product-oriented is to promote a culture of end-to-end accountability organizationally of the AI system. The team that's building the AI system needs to feel accountable for the AI system's behavior in production and for how it serves the business.
This is the most important tactic because once you have this kind of accountability culturally, people will decide that they're accountable, and they need to find ways to make it work because that's how they're measured. If you can promote this kind of culture, then you're already on the right path.
The point of this tactic is basically this: there's a plethora of different issues that can occur with AI models. One example we discussed was fraud detection. But it's unclear who's responsible for these kinds of problems. You need a culture in which it's obvious who's responsible and accountable, and they are measured for this.
To do that, you can make sure they have the right tools to do that. One key tool is Mona – but it's not the only tool. Other tools for validation, like model registry and experiment tracking, can also be useful.
The second thing is generating a granular understanding of the system's behavior. You can't just look at your feature distribution across the entire dataset, as you're going to lose the moment you see a problem over there. You've got to have a granular understanding.
The third one is creating business feedback-related KPIs for model performance. You must zoom out from the model and look at the entire process. Monitor different models in the same context to know what's happening and when. Sometimes the problem isn't in the actual model inputs or outputs – it's in some third-party data source. You need to monitor what's coming from there.
Finally, the fourth tactic is the one that is like the tide that raises all boats. If you have a research-oriented team, their main KPIs are their performance on their test set. When you have much better visibility into production and how your models behave there, you can feed that back into your research process to improve it.
Being product-oriented can really help you improve your research. It shouldn't come at the expense of improving research. It should definitely improve your research as well. And this makes it much easier culturally to make this shift.
On Hiring
First, giving talks like the one in Berlin is always helpful for Datalift. If you get a lot of exposure and people are interested in what you're doing, then they come over. However, just like when you're at a very early startup stage, your personal network is the most important thing. You need to have friends, friends of friends, and siblings of friends who are in the same field and whom you trust. These are the right people to bring on board if you're starting a startup.
One of the things that should be considered early on is who will be your founding team. This includes not just co-founders but also the people who you'd like to bring on board in the first year. You might not get all of them, but it's a start. As things progress, the network of networks becomes huge. Your founding team, if they're enthusiastic about what's happening and things are going well, will also bring in their own friends. This is usually the best thing that you can have. Almost all of Mona's employees thus far have come from personal networks, co-founders, or the first employees.

Diversity should also be considered from day one to allow more people to join later on and feel comfortable. If your team consists of 10 male engineers, bringing the first female engineer will be harder than having four male engineers, and now you're the first one. It just makes it much more difficult. Mona has over 50% female engineers, which wasn't hard. It came naturally from our friends' networks and worked really well for us.
We hired junior engineers once we had established the founding team, and we have people who are very knowledgeable about our engineering practices. We established a good capability to bring in junior engineers and grow them within the team. Still, we must pay close attention to avoid less convenient situations where we don't have enough senior people to help the juniors.
However, building a capable team makes things much easier because it's easier to bring in talented junior engineers than less talented senior engineers who get paid much more and are in a different place in their careers.
On Finding Exceptional Engineering Talent

For us, there's a threshold for how smart you need to be, but beyond that, the main thing we look for is a cultural fit. Once you pass this threshold, we look for traits such as enthusiasm to do hard work and being a nice team player. At this stage, everyone in the company is doing hands-on work. There's no one just managing.
We already have juniors who are now seniors and helping new juniors climb the ladder. It's impossible to build the ladder without the juniors bringing it up. That's the next step in the letter. We bring in juniors who we believe will be good leaders and provide resources to new juniors a year or two later.
We're looking for these things, and it's important for engineers to work on them. That's the general advice I can give.
On Working with Early Adopters

This task wasn't particularly challenging for us. Surprisingly, personal networks played a key role in our success. I knew the CEO of one company, and my co-founder knew the CTO of another. It also helped that we had established relationships with VCs and investors. Getting introductions to companies VCs already worked with was a great way to find design partners and measure our progress. It also allowed us to evaluate the quality of the VCs themselves.
We asked for help to meet new people and successfully made a few connections this way. Israel is a hub for AI, with many AI-centric companies established here. Even if they're headquartered in the US, many have their engineering or product teams based in Israel, particularly in Tel Aviv. This made it easy for us to network and build relationships within the local community, which is tight-knit and easy to navigate once you've established some rapport. Building friendships and relationships takes time, but we were in a good position to do so when we started.
On Prioritizing Product Development
Being a product person who is also an engineer can be extremely helpful. You can work with design partners to determine what they need from a solution. For example, one partner may need X while another needs Y. By breaking down the components of the solution, you can build something that provides both X and Y while also considering what should be shared and what should not be. This allows users to configure the software to have either X, Y, or both.
It's not an easy task, but our documentation provides a tutorial on configuring our software. We offer a no-code, low-code configuration that can be done using a graphic user interface or a JSON-based configuration file that can be managed on your Git repository. You can programmatically update Mona with this information to tell it how to build your monitoring schema, extract relevant information, and alert you on the relevant data.
So, think like a product person and work with your design partners to build a software solution that meets all of your needs.
On The ML Engineering Community in Israel
I believe that the Israeli tech community is thriving. While the Valley may have more companies, I am not as familiar with how the community operates there. In Israel, many companies are working on cool things related to ML engineering, infrastructure, and applications.
This is great because it is easy to find first customers in Hebrew, and a lot of thought leadership is coming from here. Additionally, the community is tight-knit, making it easy to connect with different people. Almost everyone you meet has some common friends, like those they served with in the army or went to high school with. It's easy to get acquainted this way. People here have a lot of pride and are happy to help one another, make each other look good, and celebrate each other's successes. It's a really great community. We have all the right WhatsApp and Facebook groups, so getting around is very easy.







Share this post